Introduction
When AI coding assistants are applied to large-scale software systems, their effectiveness hinges on how well they understand the codebase. Meta recently tackled this challenge in a massive data processing pipeline spanning four repositories, three programming languages, and over 4,100 files. Initial attempts using AI agents for development tasks fell short—they lacked the contextual awareness needed to make precise edits quickly. To solve this, Meta engineered a pre-compute engine—a swarm of more than 50 specialized AI agents that systematically analyzed every file and generated 59 concise context files. These files encoded the tribal knowledge that previously resided only in the minds of experienced engineers. The result: AI agents now have structured navigation guides for 100% of code modules (up from just 5%), covering all 4,100+ files across three repositories. Additionally, the system documented over 50 “non-obvious patterns”—design choices and relationships not immediately apparent from the code—and preliminary tests show a 40% reduction in AI agent tool calls per task. Best of all, the knowledge layer is model-agnostic, working seamlessly with most leading AI models.

The Challenge: AI Without a Codebase Map
Meta’s pipeline is config-as-code: it combines Python configurations, C++ services, and Hack automation scripts working together across multiple repositories. For example, onboarding a single data field touches six subsystems: configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts. All must remain synchronized. While Meta had already built AI-powered systems for operational tasks—scanning dashboards, matching patterns against historical incidents, and suggesting mitigations—extending this to development tasks proved problematic. The AI had no map. It didn’t know that two configuration modes use different field names for the same operation (swapping them leads to silent wrong output), or that dozens of “deprecated” enum values must never be removed because serialization compatibility depends on them. Without this context, agents would guess, explore, guess again, and often produce code that compiled but was subtly wrong.
The Solution: A Swarm of Specialized AI Agents
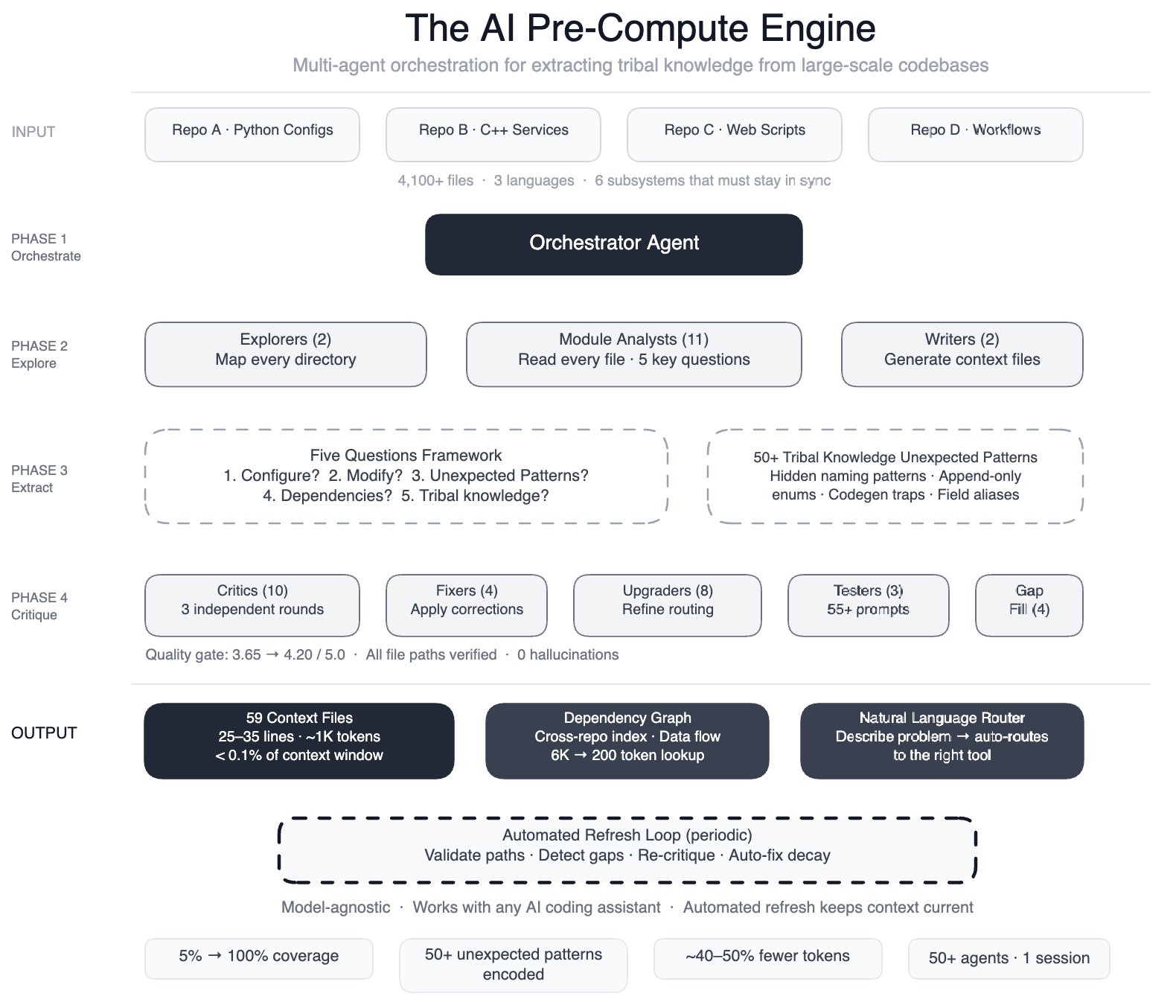
To overcome this, Meta employed a large-context-window model and task orchestration to structure the work in well-defined phases:
- Two explorer agents mapped the codebase.
- Eleven module analysts read every file and answered five key questions.
- Two writers generated context files.
- Ten+ critic passes ran three rounds of independent quality review.
- Four fixers applied corrections.
- Eight upgraders refined the routing layer.
- Three prompt testers validated 55+ queries across five personas.
- Four gap-fillers covered remaining directories.
- Three final critics ran integration tests.
In total, over 50 specialized tasks were orchestrated in a single session. The output was a set of 59 compact context files that served as structured navigation guides, encoding the tribal knowledge previously locked in engineers’ heads.
How the System Works
The pre-compute engine operates before AI agents begin their development tasks. It pre-processes the entire codebase, extracting relationships, design intent, and subtle constraints. For example, it identifies which enum values are never to be removed due to serialization dependencies, and it notes when configuration fields must match across different modes. These insights are stored in the context files, which are then loaded by the AI agents at runtime, giving them a ready-made understanding of the code’s hidden structure.
Self-Maintaining Knowledge Layer
The system is not static. Periodic automated jobs validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references. This ensures the knowledge layer remains up to date even as the code evolves. In essence, the AI isn’t just a consumer of this infrastructure—it’s the engine that runs it. The maintenance cycle runs every few weeks, keeping the context files accurate without manual intervention.
Results and Impact
The impact has been significant. Before the pre-compute engine, only 5% of code modules had structured navigation guides. After implementation, coverage rose to 100%. The documentation of non-obvious patterns helps engineers and AI alike avoid subtle errors. Preliminary tests show 40% fewer AI agent tool calls per task, meaning agents can reach the correct solution more directly. The system is model-agnostic, so it works with leading AI models like GPT-4, Claude, and others. This allows Meta to swap models without retraining the knowledge layer.
Conclusion
Meta’s approach demonstrates that for AI coding assistants to be truly effective in large, complex codebases, they need more than raw code access—they need a curated map of the design decisions and implicit rules that engineers hold. By building a pre-compute engine with a swarm of specialized AI agents, Meta turned a tangled web of repositories into a well-documented, AI-friendly environment. The result is faster, more accurate development support, and a scalable pattern that can be applied to any organization dealing with massive, multi-language pipelines.